手把手教你部署本地DeepSeek R1,打造你专属的私有大模型。
你也可以直接下载PDF文档:【☞ 云盘下载 ☜】
⼀、简介
Deepseek R1 是⽀持复杂推理、多模态处理、技术⽂档⽣成的⾼性能通⽤⼤语⾔模型。本⼿册为技术团队提供完整的本地部署指南,涵盖硬件配置、国产芯⽚适配、量化⽅案、异构⽅案、云端替代⽅案及完整671B MoE模型的部署⽅法。
核⼼提示
个⼈⽤户:不建议部署32B及以上模型,硬件成本极⾼且运维复杂。
企业⽤户:需专业团队⽀持,部署前需评估ROI(投资回报率)。
⼆、本地部署核⼼配置要求
模型参数与硬件对应表
| 模型参数(B) | Windows 配置要求 | Mac 配置要求 | 适⽤场景 |
|---|---|---|---|
| 1.5B | - RAM: 4GB- GPU: 集成显卡/现代CPU - 存储: 5GB | - 内存: 8GB(M1/M2/M3) - 存储: 5GB | 简单⽂本⽣成、基础代码补全 |
| 7B | - RAM: 8-10GB- GPU: GTX 1680(4-bit量化) - 存储: 8GB | - 内存: 16GB(M2Pro/M3) - 存储: 8GB | 中等复杂度问答、代码调试 |
| 8B | - RAM: 16GB- GPU: RTX 4080(16GB VRAM) - 存储: 10GB | - 内存: 32GB(M3Max) - 存储: 10GB | 中等复杂度推理、⽂档⽣成 |
| 14B | - RAM: 24GB- GPU: RTX 30U0(24GB VRAM) - 存储: 20GB | - 内存: 32GB(M3Max) - 存储: 20GB | 复杂推理、技术⽂档⽣成 |
| 32B | 企业级部署(需多卡并联) | 暂不⽀持 | 科研计算、⼤规模数据处理 |
| 70B | 企业级部署(需多卡并联) | 暂不⽀持 | ⼤规模推理、超复杂任务 |
| 671B | 企业级部署(需多卡并联) | 暂不⽀持 | 超⼤规模科研计算、⾼性能计算 |
算⼒需求分析
| 模型版本 | 参数(B) | 计算精度 | 模型⼤⼩ | VRAM 要求(GB) | 参考GPU配置 |
|---|---|---|---|---|---|
| DeepSeek-R1 | 671B | FP8 | ~1,342GB | ≥1,342GB | 多GPU配置(如:NVIDIA A100 80GB*16) |
| DeepSeek-R1- Distill-Llama-70B | 70B | BF16 | 43GB | ~32.7GB | 多GPU配置(如:NVIDIA A100 80GB*2) |
| DeepSeek-R1- Distill-Qwen-32B | 32B | BF16 | 20GB | ~14.UGB | 多GPU配置(如:NVIDIA RTX 40U0*4) |
| DeepSeek-R1- Distill-Qwen-14B | 14B | BF16 | UGB | ~6.5GB | NVIDIA RTX 308010GB 或更⾼ |
| DeepSeek-R1- Distill-Llama-8B | 8B | BF16 | 4.UGB | ~3.7GB | NVIDIA RTX 30708GB 或更⾼ |
| DeepSeek-R1- Distill-Qwen-7B | 7B | BF16 | 4.7GB | ~3.3GB | NVIDIA RTX 30708GB 或更⾼ |
| DeepSeek-R1- Distill-Qwen-1.5B | 1.5B | BF16 | 1.1GB | ~0.7GB | NVIDIA RTX 306012GB 或更⾼ |
算⼒匹配
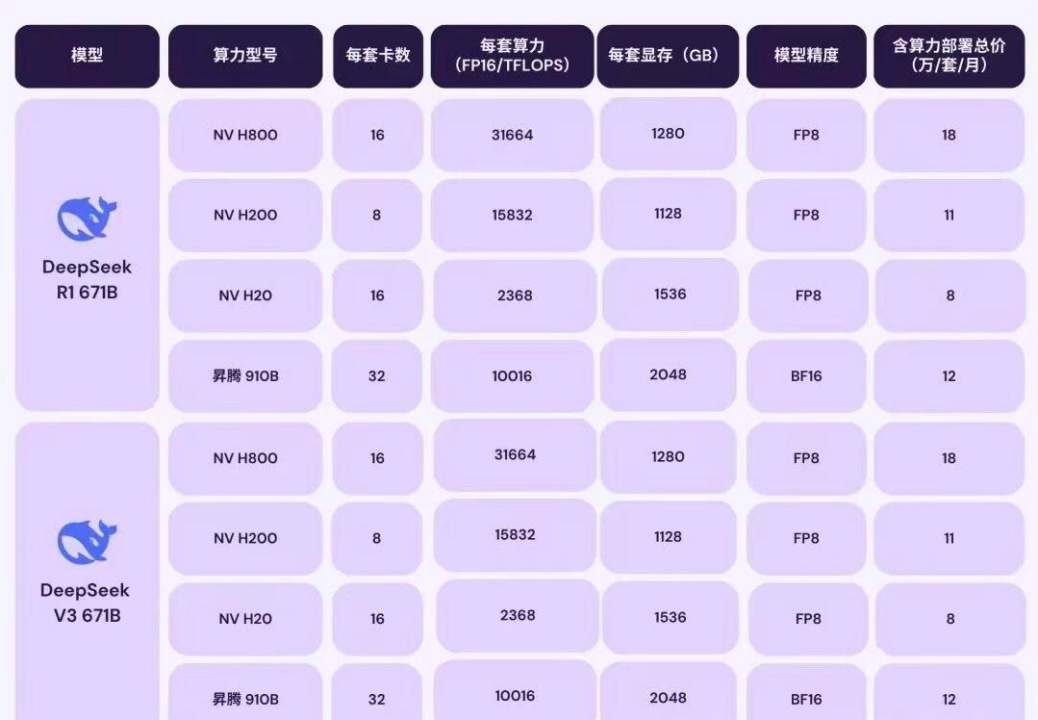
补充说明:
- VRAM 要求:表中列出的VRAM需求为最低要求,实际部署时建议预留20%-30%的额外显存以应对模型加载和运⾏中的峰值需求。
- 多GPU配置:对于⼤规模模型(如32B+),建议使⽤多GPU并联以提升计算效率和稳定性。
- 计算精度:FP8和BF16为当前主流的⾼效计算精度,能够在保证模型性能的同时降低显存占⽤。
- 适⽤场景:不同参数规模的模型适⽤于不同复杂度的任务,⽤户可根据实际需求选择合适的模型版本。
- 企业级部署:对于671B等超⼤规模模型,建议使⽤专业级GPU集群(如NVIDIA A100)进⾏部署,以满⾜⾼性能计算需求。
三、国产芯⽚与硬件适配⽅案
国内⽣态合作伙伴动态
| 企业 | 适配内容 | 性能对标(对比NVIDIA) |
|---|---|---|
| 华为昇腾 | 昇腾U10B原⽣⽀持R1全系列,提供端到端推理优化方案 | 等效A100(FP16) |
| 沐曦GPU | MXN系列⽀持70B模型BF16推理,显存利⽤率提升 30% | 等效RTX 30U0 |
| 海光DCU | 适配V3/R1模型,性能对标NVIDIA A100 | 等效A100(BF16) |
国产硬件推荐配置
| 模型参数 | 推荐⽅案 | 适⽤场景 |
|---|---|---|
| 1.5B | 太初T100加速卡 | 个⼈开发者原型验证 |
| 14B | 昆仑芯K200集群 | 企业级复杂任务推理 |
| 32B | 壁彻算⼒平台+昇腾U10B集群 | 科研计算与多模态处理 |
四、云端部署替代⽅案
国内云服务商推荐
| 平台 | 核⼼优势 | 适⽤场景 |
|---|---|---|
| 硅基流动 | 官⽅推荐API,低延迟,⽀持多模态模型 | 企业级⾼并发推理 |
| 腾讯云 | ⼀键部署+限时免费体验,⽀持VPC私有化 | 中⼩规模模型快速上线 |
| PPIO派欧云 | 价格仅为OpenAI 1/20,注册赠5000万tokens | 低成本尝鲜与测试 |
国际接⼊渠道(需魔法或外企上⽹环境)
- 英伟达NIM:企业级GPU集群部署
- Groq:超低延迟推理
五、Ollama+Unsloth 部署
量化⽅案与模型选择
| 量化版本 | ⽂件体积 | 最低内存+显存需求 | 适⽤场景 |
|---|---|---|---|
| DeepSeek-R1-UD-IQ1_M | 158 GB | ≥200 GB | 消费级硬件(如MacStudio) |
| DeepSeek-R1-Q4_K_M | 404 GB | ≥500 GB | ⾼性能服务器/云GPU |
下载地址:
- HuggingFace模型库:https://huggingface.co/models
- Unsloth AI官⽅说明:https://unsloth.ai/docs
硬��件配置建议
| 硬件类型 | 推荐配置 | 性能表现(短⽂本⽣成) |
|---|---|---|
| 消费级设备 | Mac Studio(1U2GB统⼀内存) | 10+ token/秒 |
| ⾼性能服务器 | 4×RTX 40U0(U6GB显存+384GB内存) | 7-8 token/秒(混合推理) |
部署步骤(Linux示例)
-
安装依赖⼯具:
# 安装llama.cpp(⽤于合并分⽚⽂件)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
brew install llama.cpp -
下载并合并模型分⽚:
llama-gguf-split --merge DeepSeek-R1-UD-IQ1_M-00001-of-00004.gguf DeepSeek-R1-UD-IQ1_S.gguf -
安装Ollama:
curl -fsSL https://ollama.com/install.sh | sh -
创建Modelfile:
FROM /path/to/DeepSeek-R1-UD-IQ1_M.gguf
PARAMETER num_gpu 28 # 每块RTX 4090加载7层(共4卡)
PARAMETER num_ctx 2048
PARAMETER temperature 0.6
TEMPLATE "<|end▁of▁thinking|>{{ .Prompt }}<|end▁of▁thinking|>" -
运⾏模型:
ollama create DeepSeek-R1-UD-IQ1_M -f DeepSeekQ1_Modelfile
ollama run DeepSeek-R1-UD-IQ1_M --verbose
性能调优与测试
GPU利⽤率低:升级⾼带宽内存(如DDR5 5600+)。
扩展交换空间:
sudo fallocate -l 100G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
满⾎671B部署命令
VLLM
vllm serve deepseek-ai/deepseek-r1-671b --tensor-parallel-size 2 --max-model- len 32768 --enforce-eager
SGLang
python3 -m sglang.launch_server --model deepseek-ai/deepseek-r1-671b --trust- remote-code --tp 2
六、注意事项与⻛险提示
-
成本警示:
- 70B模型:需3张以上80G显存显卡(如RTX A6000),单卡⽤户不可⾏。
- 671B模型:需8xH100集群,仅限超算中⼼部署。
-
替代⽅案:
- 个⼈⽤户推荐使⽤云端API(如硅基流动),免运维且合规。
-
国产硬件兼容性:需使⽤定制版框架(如昇腾CANN、沐曦MXMLLM)。
七、异构gpustack⽅案
GPUStack开源项⽬ https://github.com/gpustack/gpustack/
模型资源测算⼯具 GGUF Parser(https://github.com/gpustack/gguf-parser-go)来⼿动计算的显存需求。
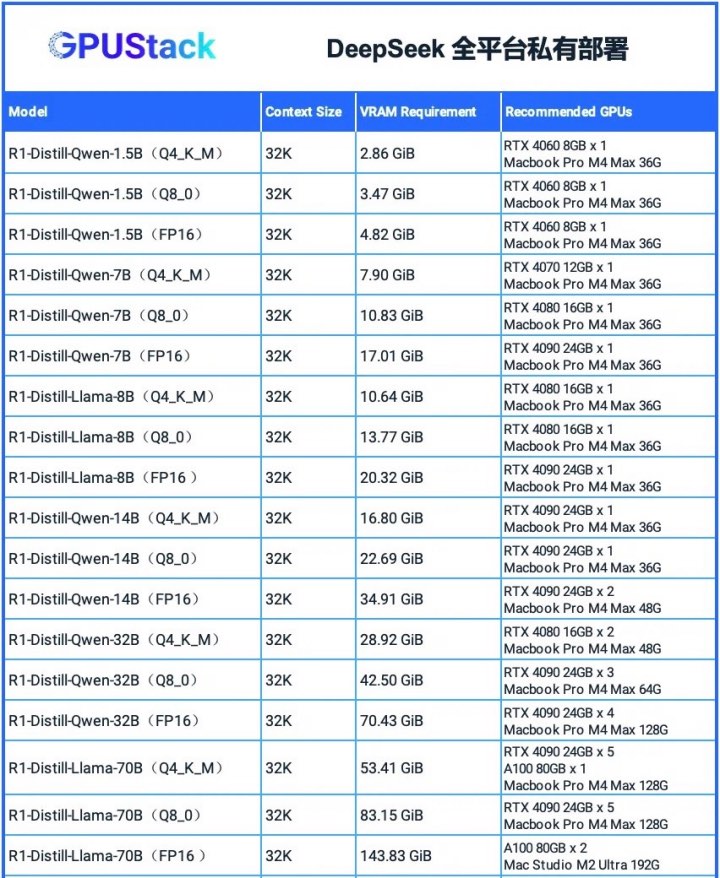
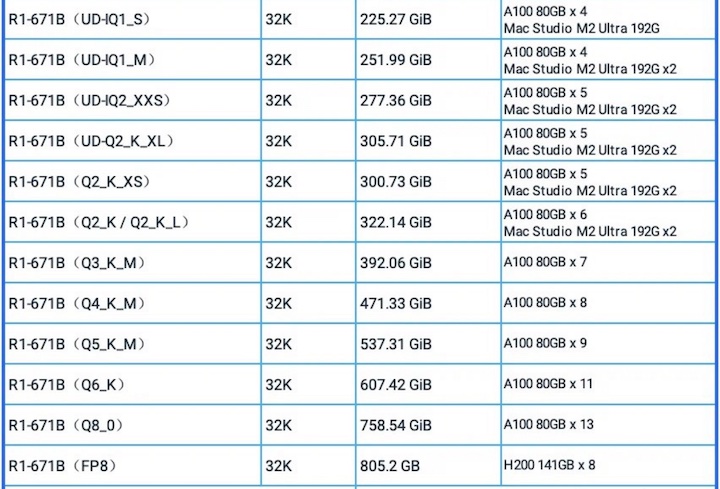
结语
Deepseek R1 的本地化部署需极⾼的硬件投⼊与技术⻔槛,个⼈⽤户务必谨慎,企业⽤户应充分评估需求与成本。通过国产化适配与云端服务,可显著降低⻛险并提升效率。技术⽆⽌境,理性规划⽅能降本增效!
全球企业个⼈渠道附表
-
秘塔搜索:https://metaso.cn
-
360纳⽶AI搜索:https://www.n.cn/
-
字节跳动⽕⼭引擎:https://console.volcengine.com/ark/region:ark+cn-beijing/experience
-
百度云千帆:https://console.bce.baidu.com/qianfan/modelcenter/model/buildIn/list
-
Groq:https://groq.com/
-
Chutes:https://chutes.ai/app/chute/
-
Github:https://github.com/marketplace/models/azureml-deepseek/DeepSeek-R1/playground
-
Cursor:https://cursor.sh/
-
Lambda:https://lambdalabs.com/
-
Cerebras:https://cerebras.ai
-
Perplexity:https://www.perplexity.ai
-
阿⾥云百炼:https://api.together.ai/playground/chat/deepseek-ai/DeepSeek-R1